This year I realized that what I tell students, “If the writing is hard, you have not done enough reporting,” is true also for academic papers and projects. Having to find / read / understand / synthesize dozens of research papers and book chapters is not a skill I had to formally develop when I was in school. But recently, several short and long-term writing projects have shown the folly of having no process. I needed to read more, but also manage the information better.
So to further procrastinate on actually writing, I spent a couple of weeks on-and-off improving my workspace. Details below. FWIW, I have a Mac and some of the apps are Mac-only. There might be PC-alternatives but I have not looked into those.
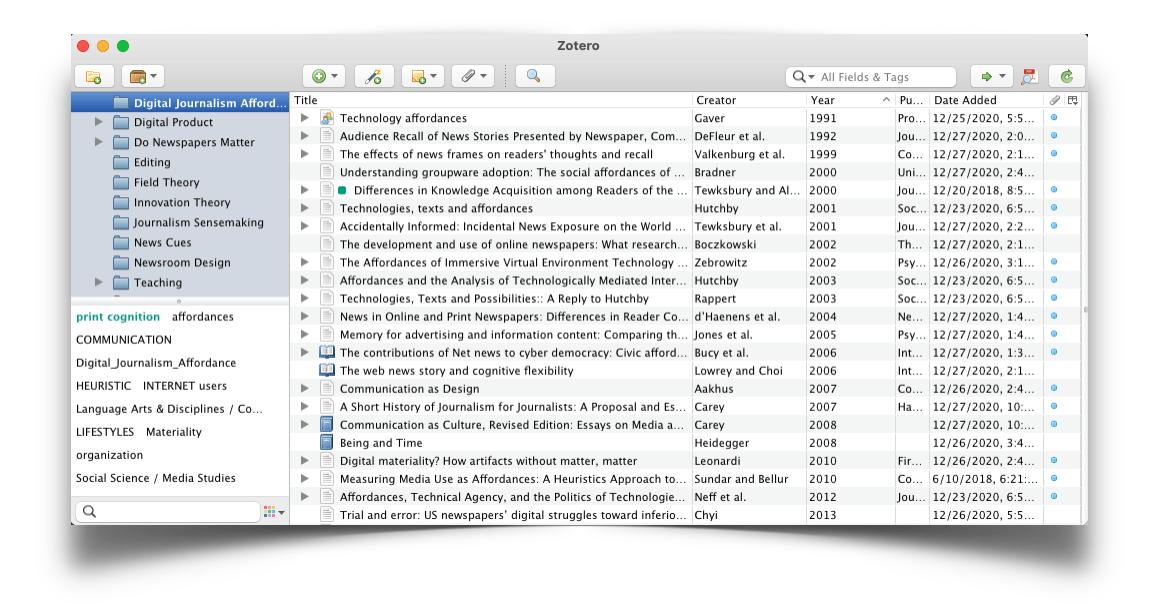
After test-driving EndNote and Mendeley a few years ago, I settled on Zotero as a reference manager. It is free, open-source and has a decent development community. That is important as the user-developed plug-ins are key. It does not yet have an iOS app, though PaperShip still more or less works.
Some of these tools require a familiarity with Python and tools like HomeBrew for installing and managing software packages like PyZotero. Each app includes documentation and walk-throughs that you can learn from if you take it slow. A full list of apps, tools and links is at the bottom.
Finding, reading, annotating, archiving
- Install Zotero
- Grab the appropriate Zotero Connectors for your desktop browsers. This lets you save references directly from your desktop into Zotero to either the web or the desktop app. And, if your library has access to paid academic journals AND allows off-campus proxy server access, the connector makes that facilitation seamless.

At Mizzou this means Google Scholar is proxied and search results are either one-click away from the article PDF or a “Find it at MU” link is inserted onto the page.
- Two other Zotero add-ons are invaluable: ZotFile lets you automatically rename, move, and attach PDFs AND extract annotations from PDF files. Zotero OCR does what it says and is a quick way to convert older scanned documents to text PDFs. You need to install Tesseract to power the PDF conversions.
My workflow is: Use Google Scholar to find relevant journal articles, one-click download them into Zotero, OCR if necessary and then highlight and leave notes in the PDF as I read. I then go to the collection of references I am working with and select “extract annotations” which creates an attached RTF file with every highlighted word and note. This alone is a huge time saver.You can just ignore the rest of my list here and happily get the above tools up-and-running in fifteen minutes.
Information management
Having easy access to the annotations is great, but they are still isolated across 20–30 files in a Zotero collection. For convenience, I really want to gather all of the Product Management notes (for example) into one file for reference.
- PyZotero is a Python wrapper for the Zotero API giving you programmatic access to every field and file.
- Zotero Workflows are a set of scripts I wrote that use PyZotero to look for extracted annotations, and aggregate them based on group, collection or search term.

The workflows are all fairly simple Python scripts but they combine the highlights and notes from dozens of PDF files into one text document making it much easier to find and use a reference I read a month ago. The RTF file also includes an anchor link back to the original PDF so it is an easy index of what I have read on a given topic.
Workflows
- After getting the annotation scripts working, I broke down and bought Alfred for Mac to power hotkeys, automated workflows and custom search engines.
- You can write your own basic scripts, or download workflows such as Alfred PDF Tools which allows quick optimization, merging and splitting of PDFs.
I have done three things with Alfred:
- Set up custom searches for Google Scholar and the Mizzou Library that allow keystroke access to query either site using the off-campus proxy.
- Set up hotkeys that quickly open the websites I use multiple times daily at work
- Using my Python annotation scripts, set up a workflow to query for a list of Zotero collections and, let me select from the list, and then create an extracted notes file for that collection.
Finally, not at all required in the process, but I also use DevonThink as a local archive and search engine for everything that does not go into Zotero. So all of the extracted notes files are indexed by DevonThink and also made available on my mobile devices for easy access.
For actual writing, I am using Scrivener. Notice how that comes last on the list. There are some interesting possibilities there to further integrate Zotero’s citations during writing and output but I have not yet gotten that far.
List of ingredients